Best Web Search APIs in 2026
Not all web search APIs do the same thing. Some return ranked snippets in under a second; others scan tens of thousands of pages to find everything relevant.
Which one belongs in your stack depends on the kind of questions you're trying to answer and how much it costs you to miss a result.
This list covers seven APIs that developers are actually deploying in 2026, across general search, AI agent pipelines, semantic retrieval, and enterprise event monitoring.
Each has a different indexing approach, output format, and pricing model. The profiles below cover what each one actually does well – and where it runs out of road.
Table 1. Quick comparison: web search APIs in 2026
|
API / Tool |
Indexing model |
Output type |
Pricing |
Free tier |
|
CatchAll |
Proprietary 2B+ page index |
Structured JSON + entity metadata |
Per result |
No |
|
Tavily |
Aggregated, LLM-optimised |
Scored snippets + synthesis |
Per-query credits |
Yes (limited) |
|
ScaleSerp |
Google SERP proxy |
JSON (SERP data) |
Monthly tiers |
Trial only |
|
Diffbot |
Own crawler + knowledge graph |
Structured entity data |
Enterprise custom |
No |
|
Zenserp |
Google SERP proxy |
JSON (SERP data) |
Per-query bundles |
Yes |
|
DataForSEO SERP |
Multi-engine SERP proxy |
JSON (multi-engine) |
Pay-as-you-go |
No |
|
Kagi Search API |
Curated, ad-free index |
JSON / summariser output |
Credit-based |
No |
Web search API profiles
CatchAll
Catchall is a recall-first search API, built for teams that need to find every relevant result – not just the highest-ranked ones. The core difference is architectural: instead of pulling the top 10–20 pages from a rankings list, CatchAll scans 50,000+ pages per job across a proprietary index of over 2 billion pages, then returns structured JSON with entity tags, source metadata, and publication dates already extracted.
That matters in workflows where a missed result is an actual business problem. A supply chain risk team that misses one factory-closure notice, or a compliance function that skips a regulatory update, doesn’t just get a slightly incomplete answer – it gets the wrong one. NewsCatcher benchmarks CatchAll’s recall at 86%, versus roughly 16% for OpenAI Deep Research on comparable enumeration tasks. Pricing is per result rather than per query, so cost scales with what you actually retrieve.
On top of the web search API sits a monitoring function: configure an alert, and CatchAll surfaces new matches automatically as they appear in the index. For teams running continuous intelligence workflows, that removes the need to re-query on a schedule.
Best for: Enterprise intelligence teams tracking regulatory filings, M&A signals, or supply chain events; AI agents where missing a document has downstream consequences.
Tavily
Tavily abstracts the full search-and-extract loop into a single API call. Send a query; get back cleaned, relevance-scored snippets with optional answer synthesis. The architecture is designed for speed in agent pipelines rather than exhaustive coverage. Its p50 latency sits around 180ms, and native integrations exist for LangChain, LlamaIndex, CrewAI, and AutoGen, which means most teams don’t need to write any connector code.
The trade-off is depth. Tavily optimises for returning a few strong results fast. For enumeration tasks – “find all instances of X” rather than “find me something about X” – it’s the wrong architecture. For conversational agents and general Q&A, it’s usually the right starting point.
Best for: LLM agent developers who need fast, agent-native search with minimal integration overhead; prototyping and conversational Q&A pipelines.
ScaleSerp
ScaleSerp is a Google SERP API built for volume and reliability. It handles the proxying, rendering, and parsing infrastructure and returns clean JSON covering organic results, featured snippets, People Also Ask, image packs, and related searches. The main use case is pipelines that need Google ranking data at scale without maintaining scraping infrastructure.
It does not extract content from the pages themselves – you get SERP metadata, not document text. For SEO monitoring tools, rank trackers, and competitive research pipelines, that’s all they need. For anything that requires reading the actual page, a separate extraction step is required.
Best for: SEO software, rank tracking pipelines, and any workflow that needs high-volume, reliable Google SERP data in JSON.
Diffbot
Diffbot sits in a different category. Rather than returning search results, it extracts structured data from web pages and maintains a continuously updated knowledge graph covering over a billion entities – companies, people, products, and articles. The extraction engine uses computer vision alongside HTML parsing, which makes it more robust on complex or poorly structured pages than most alternatives.
The two main use cases are B2B data enrichment (feeding CRM or sales tools with company and contact data) and structured extraction from article or product pages at scale. It’s enterprise-priced and suited to teams with real data infrastructure requirements, not side projects.
Best for: B2B data enrichment products, entity extraction pipelines, and teams building on top of structured company or product data.
Zenserp
Zenserp is the lightest option here. It proxies Google search results and returns standard JSON – organic results, news, local, and image results depending on the query type. The setup is minimal, the documentation is clear, and there’s a free tier that’s actually usable for testing.
It doesn’t compete with ScaleSerp or DataForSEO on volume capacity, SLA guarantees, or feature breadth. For small internal tools, early-stage prototypes, or projects where the query volume doesn’t justify paying for production-grade infrastructure, it’s a sensible choice.
Best for: Small-scale SERP data needs, internal tools, and developers testing a concept before committing to a production-grade solution.
DataForSEO SERP API
DataForSEO covers the broadest range of search engines in this list: Google, Bing, Yahoo, Baidu, Naver, and others, with location targeting down to city level. Output includes organic results, local packs, featured snippets, shopping results, and reviews, depending on the endpoint. Pricing is pay-as-you-go per task, which works well for uneven query volumes.
The complexity is real. There are many endpoint types and result formats to navigate, and teams new to the API usually spend time orienting before they get to the data they actually need. For SEO software products and teams that genuinely need multi-engine or geo-specific data, that’s a reasonable trade-off.
Best for: SEO software developers, rank tracking at scale, and teams that need multi-engine or location-specific SERP data.
Kagi Search API
Kagi is an ad-free, subscription search engine that launched a developer API in 2024. Its results are curated to reduce SEO-gamed and content-farm output, which produces noticeably different results from Google or Bing in certain query categories – particularly for research, technical, and professional topics. The Summariser API returns citation-backed answer summaries on top of standard search results.
The volume ceiling is the main constraint. Kagi is credit-based and not designed for high-throughput pipelines. For applications where result quality matters more than query volume – professional research assistants, academic tools, internal knowledge search – it’s worth a trial.
Best for: Research and knowledge tools where source quality and absence of ad-optimised content is a feature; low-to-medium query volume.
Table 2. How the seven APIs compare in recall depth, latency, and cost
Every API in this list trades off three variables: how completely it covers the web, how fast it responds, and what that costs at scale. The table below maps those trade-offs directly.
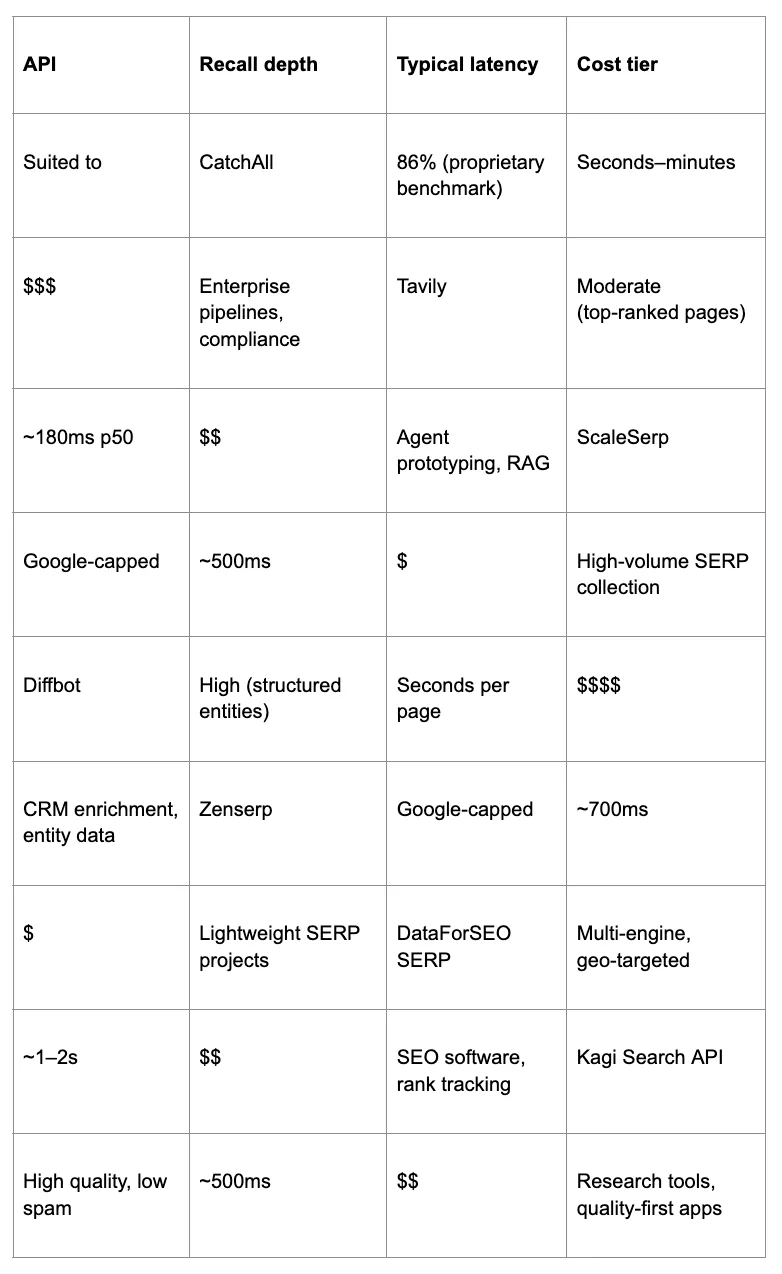
Table 3. Integration effort and developer experience
Time-to-first-result varies a lot across these APIs – not just because of latency, but because of how much setup sits between you and a working call. This table covers setup complexity, SDK support, and the practical notes that tend to surface once teams get past the documentation.
|
API |
Protocol |
Setup effort |
Official SDKs |
Integration notes |
|
CatchAll |
REST |
Moderate |
Python, JS |
Best when pipeline needs structured events, not just snippets |
|
Tavily |
REST + native |
Low |
Python, JS, Go |
Pre-built in LangChain, LlamaIndex, CrewAI, AutoGen |
|
ScaleSerp |
REST |
Low |
None official |
Drop-in JSON for existing scraping or SEO pipelines |
|
Diffbot |
REST |
High |
Python, JS |
Needs data model planning; strong for entity graph work |
|
Zenserp |
REST |
Very low |
None official |
Quickest to get running; limited docs for edge cases |
|
DataForSEO SERP |
REST |
Moderate |
Python, PHP |
Many endpoint types; budget time for endpoint selection |
|
Kagi Search API |
REST |
Low |
None official |
Clean API; volume limits require careful query budgeting |
How to choose a web search api
The right API depends on what failing to find a result actually costs in your context. For general agent Q&A, the cost of a missed result is low. For compliance tracking or supply chain monitoring, it’s not. Start there, then match against latency, budget, and integration constraints.
Table 4. Situation-based decision guide
|
Situation |
What matters most |
Reach for |
Skip it if |
|
Building an agent that tracks real-world events |
Recall depth + structured output |
CatchAll |
Latency under 1s is a hard requirement |
|
Prototyping an LLM chatbot or Q&A tool |
Speed + framework support |
Tavily |
Completeness of results matters |
|
Running SEO reports or rank tracking at volume |
Google SERP data + throughput |
ScaleSerp |
You need more than SERP metadata |
|
Enriching B2B company or contact records |
Structured entity data + freshness |
Diffbot |
Budget is tight – pricing is enterprise-tier |
|
Testing a concept before committing to a paid API |
Free tier + minimal setup |
Zenserp or Kagi |
You need production-grade SLAs |
|
Building SEO tooling across multiple markets |
Multi-engine + geo-level targeting |
DataForSEO SERP |
You only need Google results |
|
Research tool where source quality matters |
Ad-free, curated index + summariser |
Kagi Search API |
Query volume is high – cost compounds quickly |
Bottom line
These seven APIs are not interchangeable. Tavily is for agent developers who need something working by the end of the afternoon. CatchAll is for teams where a single missed result has a measurable business cost. ScaleSerp and DataForSEO are infrastructure tools for SEO pipelines, not general search. Diffbot is a data product, not a search API in the traditional sense. Zenserp and Kagi serve opposite ends of the quality-versus-volume spectrum.
Choose based on what ‘finding results’ means in your specific context – and on what happens when the API misses one.