Understand Apache Kafka Partitions and Brokers - A Comprehensive Guide to System Design
Do you need to understand Apache Kafka topics better? Want to know what partitions and brokers are all about in the Apache Kafka system?
Understanding key concepts like these can make a big difference when working with streaming data. In this comprehensive guide, we'll be discussing the fundamentals of partitions and brokers in Apache Kafka, teaching you how they work together so that you can create effective data pipelines and start processing streams with ease. Keep reading to learn more!
Apache Kafka and its Brokers & Partitions?
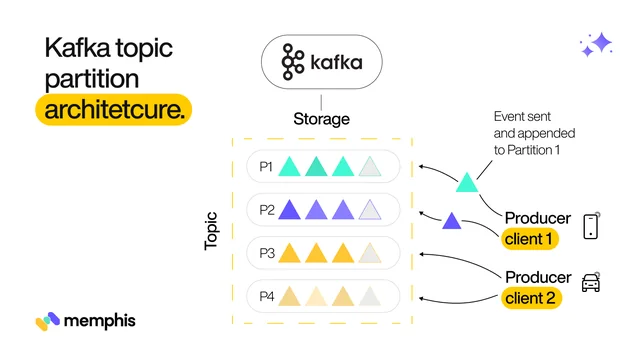
Apache Kafka is a revolutionary system for messaging and streaming data. Its unique design allows it to rapidly process large amounts of data with unrivaled scalability and performance. Central to the Kafka system design are Kafka brokers and Kafka partitions. Each Kafka broker is responsible for hosting a portion of Kafka topics, divided into partitions containing log files of data records.
Partitions are integral to Kafka's scalability and fault tolerance, allowing topics to be distributed across multiple brokers so that more message processing power can scale up with minimal disruption if one or more Kafka brokers need to go offline. As the demand for real-time data insights grows, Apache Kafka will remain an essential technology for messaging, streaming, and analytics solutions.
An Overview of Apache Kafka's Design Goals
Apache Kafka is a distributed streaming platform created with modern system design goals in mind. Its core features make it a powerful tool, allowing users to process and move data with astonishing speeds and efficiency. Many of its design goals, such as scalability, fault tolerance, low latency throughput, and automated operational complexity handling, contribute to this. Being an open-source platform also makes it highly reliable and secure while offering the capability to extend its basic functionality with pluggable designed components, which further adds to its flexibility. As a result of these considerations, Apache Kafka continues to be one of the most popular Kafka systems designs today for many developers, businesses, and organizations across the globe.
Configuring Apache Kafka Partitions and Brokers
Apache Kafka offers an effective system design for efficiently streaming large amounts of data. An essential part of this design is the partitions and brokers within Kafka clusters. Configuring Kafka partitions and brokers are essential to excellent Kafka system design and good performance. It includes choosing the desired number of nodes and replication factor, setting topic configurations like the number of partitions, selecting a broker strategy for cluster communication, and more. Such important configuration decisions largely depend on specific use cases, but understanding Kafka partitioning principles is an essential step to correctly configuring Kafka clusters to maximize their effectiveness.
Benefits of Partitioning in Apache Kafka
Partitioning is an essential Kafka system design concept that allows Kafka to handle large-scale messaging scenarios. It enables Kafka clients to balance their workloads across multiple nodes, increasing the scalability and throughput of a Kafka cluster. Additionally, partitioning helps with fault tolerance as it provides an effective way to quickly build backups for Kafka brokers for recovery and redundancy purposes. It makes Kafka more reliable in the event of any server failures or temporary outages and ensures that data remains available even in extreme failure scenarios. By efficiently utilizing partitioning, Kafka users can experience enhanced performance and quick failover times even during highly concurrent use cases. Overall, partitioning is immensely beneficial in Kafka system designs which takes advantage of Kafka's ability to handle many incoming messages quickly and reliably.
Considerations for Choosing the Right Number of Partitions & Brokers
When designing a Kafka system, there are several considerations to consider when deciding the correct number of partitions and brokers.
First, when setting the number of partitions, consider the rate at which you expect your data to grow in the future; a higher number of partitions may require more storage, but it will offer your Kafka system a greater level of scalability for future needs.
Second, the number of brokers needs to ensure that an adequate amount of machines serves all your partitions with redundancy; if too few brokers are set up, it could lead to unbalanced loads and inefficiencies.
Best Practices for Optimizing Performance in Apache Kafka with Proper Partition Sizing
When dealing with Kafka system design, proper partition sizing is one of the best practices for optimizing performance. Without this step, partitions could become unbalanced and cause broker performance issues. It’s essential to understand how to partition size affects Kafka to properly size Kafka so that it meets the throughput and latency requirements for a given application. The most important factor when considering Kafka partition sizing is the message size, as more important messages can hinder Kafka’s performance significantly due to additional operations. Other things include the number of consumers, retention times, and workload fluctuations impacting latency and throughput. With careful consideration of these factors, proper Kafka partition sizing and placement can help ensure maximum performance from your Kafka system.
Conclusion
To sum up, Apache Kafka is a powerful and versatile distributed streaming platform capable of managing large-scale message processing. Its virtual partitioning system and brokers make it easy to deploy, configure, and scale applications, making it an ideal solution for use cases requiring low latency, high scalability, and reliability. Understanding the basics of Apache Kafka's partitions and brokers is vital in ensuring successful implementations. As such, developers need to note the considerations associated with configuring Apache Kafka partitions & brokers, select accurate parameters for optimizing performance through partition sizing and identify specific best practices for smooth operation in production. With these points of reference firmly in mind, you can now confidently begin building your dynamic applications on Apache Kafka!